Slope-intercept library design
05 April 2022
The equation y=mx+b defines a line in slope-intercept form. The line will intercept the y-axis at the value b and for each change in x its slope (the amount the line goes up or down) will change by m.
Slope-intercept gives me a way to think about the design of libraries in relation to each other. The intercept is the initial cost of learning and setup for a library, and the slope is how the library's complexity changes over time. There's no real units here and the values are entirely subjective. Let's try it!
Picasso
Exactly 10 years ago today I introduced Picasso internally at Square. As an image loading library for Android, its primary selling point was a low intercept. It required no real configuration and only one line of code (even in a ListView adapter).
Picasso.with(context).load("https://...").into(imageView);
At the time this was a refreshing change from the existing libraries which required a lot of up-front and per-request configuration.
The downside, however, was that as your needs grow the slope of complexity also grows faster than desired. Configuring the global instance, managing multiple instances, intercepting requests, and transforming images are all possible but more difficult than if the library was designed differently.
Retrofit
Retrofit is a declarative HTTP client abstraction for the JVM and Android. It requires configuration of a central object before you can use it to create instances of service interfaces.
interface GitHubService {
@GET("users/{user}/repos")
Call<List<Repo>> listRepos(@Path("user") String user);
}
var retrofit = new Retrofit.Builder()
.baseUrl("https://api.github.com/")
.addConverter(MoshiJsonConverter.create())
.build();
var service = retrofit.create(GitHubService.class);
This up-front configuration gives Retrofit a higher intercept on the y-axis. Exposure to these APIs gives you an entrypoint to discover functionality and encourages you to manage their lifetimes in an efficient way for your usage allowing the slope of complexity to not be as steep.
Dagger
Dagger is an annotation processor-based dependency injection library for the JVM and Android. It has almost no API of its own aside from a handful of annotations. In order to use Dagger you need to learn dependency injection as a concept, learn how to build the various types to which its annotations apply, and then decide how dependency injection will fit into your architecture. It's just about the least turn-key library I've ever used which gives it an extremely high conceptual intercept.
@Component(modules = {
AppModule.class
})
interface AppComponent {
App app();
}
@Module
final class AppModule {
@Provides static Database provideDatabase() {
return new Database();
}
}
final class App {
private Database database;
@Inject App(Database database) {
this.database = database;
}
void run() {
System.out.println(database.getUsers());
}
public static void main(String... args) {
AppComponent.create().app().run();
}
}
That's a lot of lines to basically do new App(new Database()).run()! But of course nothing stays that simple.
Once you have Dagger fully integrated into a large application, adding and connecting new dependencies is as easy as adding a parameter. The library automatically figures out how to wire the two together and shares instances across pre-defined lifetimes. Its slope of complexity is extremely shallow.
The slope-intercept evaluations of Picasso, Retrofit, and Dagger look roughly like this:
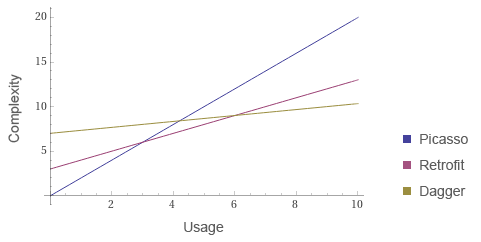
What are the units? It doesn't matter! This is a subjective approximation of concepts.
Design
Slope-intercept evaluation really shines when designing new libraries. It serves as a framework for discussing the amount of complexity you front-load onto a user and the amount which is spread over the continued usage of a library.
Can some parameter be specified globally or should it be passed with each call? Should it be available in both locations with overriding behavior? Is there an implicit default or should you always explicitly require that it is supplied?
As answers to those questions are being determined, you can start to look at the library as a whole. Can multiple parameters become a composite type? Do certain parameters imply defaults for the others? Are too many concepts being pushed into global configuration rather than local?
And finally, you can compare your design against others to determine if you're comfortable with its approximate slope and intercept. Picasso was built to combat image loading libraries whose complexity was that of Dagger. With the initial design I missed the mark and over-corrected to be too simple. Being closer to Retrofit would have been a much more comfortable place for the long-term health of the library.
Layering
Ideally every library would have an intercept near zero and a slope near zero. That is, a library which is trivial to get started with and whose API can accommodate every use case over time without learning anything new.
In practice this never happens simply due to the nature of complexity. You can't build libraries to solve non-trivial tasks while keeping the API basic and supporting myriad use cases. But what you can do is cheat by providing multiple of these hypothetical slope-intercept lines through layering.
Providing multiple APIs at different levels of abstraction allows solving 80% of use cases with a simple API, then 80% of the remaining 20% with a more detailed API, and then the final slice with a low-level API. Each layer is built on top of the next one with a measured reduction in API complexity.
In an HTTP client, for example, you can expose the declarative API for the majority, an imperative API for the minority, and then low-level protocol handlers for exotic needs. If a layer does not meet your requirements then you can always drop down to the next one for more control but also more responsibility.
And now what you've created is that exact same graph as above, except representing one library and its three layers of APIs.
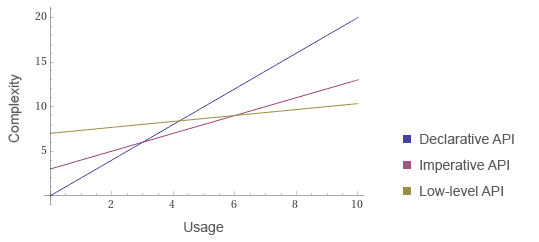
This is certainly no exact science. But perhaps it will help you build a better library in the future. It's helped me!
— Jake Wharton