Perils of duplicate finding
14 February 2024
Given an array of integers ([1, 2, 3, 1, 3, 1]), find the elements which are duplicated.
No, we're not interviewing.
I'm trying to prevent a user from specifying a reserved value twice.
Elsewhere in the file I already have duplicate detection for object tags.
val dupes: Map<Int, List<Widget>> =
widgets.groupBy(Widget::tag)
.filterValues { it.size > 1 }
I can do the same technique for the integer array with an identity function and grabbing the resulting keys.
val dupes: Set<Int> =
ints.groupBy { it }
.filterValues { it.size > 1 }
.keys
This prints [1, 3].
So… done? Yes! But no, using the map seems wasteful, right?
Attempt 1
My first attempt to avoid the map was to remove the set of integers from a list of them. This should result in a list of any duplicated elements.
val dupes: List<Int> =
ints.toList() - ints.toSet()
No matter the content of ints, this will always print [].
Why?
The minus operator says that it "returns a list containing all elements of the original collection except the elements contained in the given elements collection".
So it removes all occurrences of each element in the set from the list.
This is some surprising behavior to hide behind an operator whose signature operates on an Iterable receiver and Collection argument.
Attempt 2
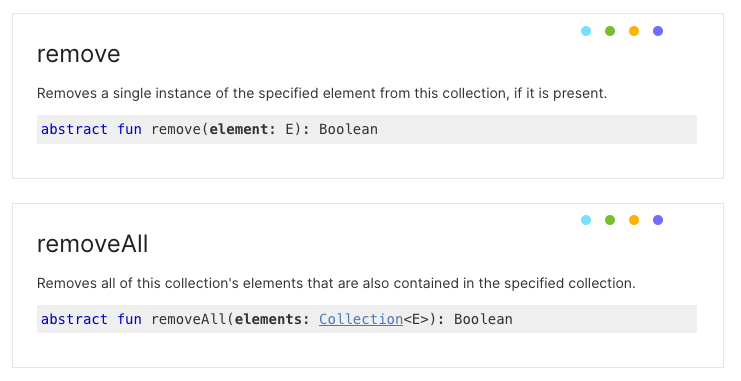
Second attempt switches to MutableList.removeAll which takes a collection of elements.
The MutableList.remove function only removes the first occurrence of an element, so this should remove the first occurrence of each element in the set.
val dupes: List<Int> =
ints.toMutableList()
.apply { removeAll(ints.toSet()) }
This once again prints [].
But why?
Kotlin made me a liar.
MutableList.remove does indeed only remove the first occurrence of the element.
MutableList.removeAll, however, removes all occurrences of each element in the supplied collection.
That's quite the subtle asymmetry.
There is no function for removing all occurrences of a single element. Nor a function to remove only the first occurrences of each element of a supplied collection.
You needn't be mad at Kotlin, though. It inherited this behavior from Java.
Attempt 3
Third attempt now with MutableList.remove.
val dupes: List<Int> =
ints.toMutableList()
.apply { ints.toSet().forEach(::remove) }
This (finally) prints [1, 3, 1].
If we want just the set of duplicates to match the map-based approach above we can tag on a toSet().
val dupes: Set<Int> =
ints.toMutableList()
.apply { ints.toSet().forEach(::remove) }
.toSet()
Visually this is not the greatest.
It's also not really that efficient (not that we've been worrying about that yet).
We got here because I started with a clever-but-incorrect approach (toList() - toSet()) that I then had to refactor until it was correct.
Attempt 4
Fourth attempt is a chance to reset our approach.
I thought that we could partition the elements based on whether we've seen the value before.
A set tracks the values, and its MutableSet.add returns a boolean indicating whether the collection was mutated (i.e., has been seen before).
val dupes: Set<Int> =
HashSet<Int>()
.run { ints.partition(::add) }
.second
.toSet()
This prints [1, 3] correctly.
Visually the code is just dreadful.
It's hard to quickly discern what value is flowing from line to line.
Using partition was just my first intuition.
But a partition that throws away half the result has another name: a filter!
Attempt 5
Fifth attempt at this now using a filter.
val dupes: Set<Int> =
ints.filterNot(HashSet<Int>()::add)
.toSet()
This continues to print [1, 3] correctly.
We use filterNot because we want to keep elements where MutableSet.add returns false.
Visually this is pretty decent.
The use of HashSet<Int>()::add is what's known as a bound reference.
We are specifying a function reference of MutableSet::add as our filterNot lambda, but bound to an instance of HashSet which we are creating on-the-fly.
This is an equivalent version of the above code.
val seen = HashSet<Int>()
val dupes: Set<Int> =
ints.filterNot(seen::add)
.toSet()
The advantage of inlining the HashSet instantiation is that we don't need to name it.1
Attempt 5.1
Finally, almost all of Kotlin's collection extensions have To-suffixed variants which allow supplying a destination collection.
This can save you from having to add a toSomething() after an operation by instead just using that Something in the operation directly.
val dupes: Set<Int> =
ints.filterNotTo(HashSet(), HashSet<Int>()::add)
Pretty, pretty, pretty good.
Benchmarks
Performance is not really a concern in my usage, but let's look anyway.
Benchmark Score Error Units
---------------------------------------------- --------- ------ -----
IntDupes.map 94.015 ± 0.469 ns/op
IntDupes.map:·gc.alloc.rate.norm 776.000 ± 0.001 B/op
IntDupes.mutableListRemove 155.744 ± 17.829 ns/op
IntDupes.mutableListRemove:·gc.alloc.rate.norm 560.000 ± 0.001 B/op
IntDupes.partition 135.693 ± 18.976 ns/op
IntDupes.partition:·gc.alloc.rate.norm 544.000 ± 0.001 B/op
IntDupes.filterNot 97.748 ± 1.055 ns/op
IntDupes.filterNot:·gc.alloc.rate.norm 504.000 ± 0.001 B/op
IntDupes.filterNotTo 39.904 ± 0.331 ns/op
IntDupes.filterNotTo:·gc.alloc.rate.norm 432.000 ± 0.001 B/op
So the filterNotTo winds up being the fastest and allocates the fewest bytes.
Double win!
-
As I'm writing this I'm realizing the
partitionabove could have beenints.partition(HashSet<Int>::add).second.toSet(). This produces the same bytecode, but from a more compact Kotlin. ↩
— Jake Wharton